Webman AI + DeepSeek本地训练,打造私有知识库
Webman AI 发布5.4.0版本,支持选择任意embedding模型,这一突破性更新使得用户能够将Webman AI与本地
DeepSeek等开源模型无缝结合,打造专属的私有知识库系统。通过本地化训练与部署,用户可以无需依赖网络连接即可实现内部专有AI知识库助理。
以下是完整的教程,如果你之前执行过相关训练操作,有些步骤可以直接跳过。
训练模块部署步骤
假设你已经安装了webman/ai
步骤一:安装redis-stack服务端(注意普通redis-server服务端不支持,要用redis-stack才行)
docker pull docker.1ms.run/redis/redis-stack
mkdir /home/data/redis -p
docker run --name redis-stack -v /home/data/redis:/data -p 6380:6379 -d redis/redis-stack步骤二:给webman安装illuminate/redis组件
webman-v2版本 webman根目录执行
composer require -W webman/redis illuminate/eventswebman-v1版本 webman根目录执行
composer require -W illuminate/redis illuminate/events步骤三:配置redis
新建 plugin/ai/config/redis.php,内容如下
<?php
return [
'default' => [
'host' => '127.0.0.1',
'password' => null,
'port' => 6380,
'database' => 0,
],
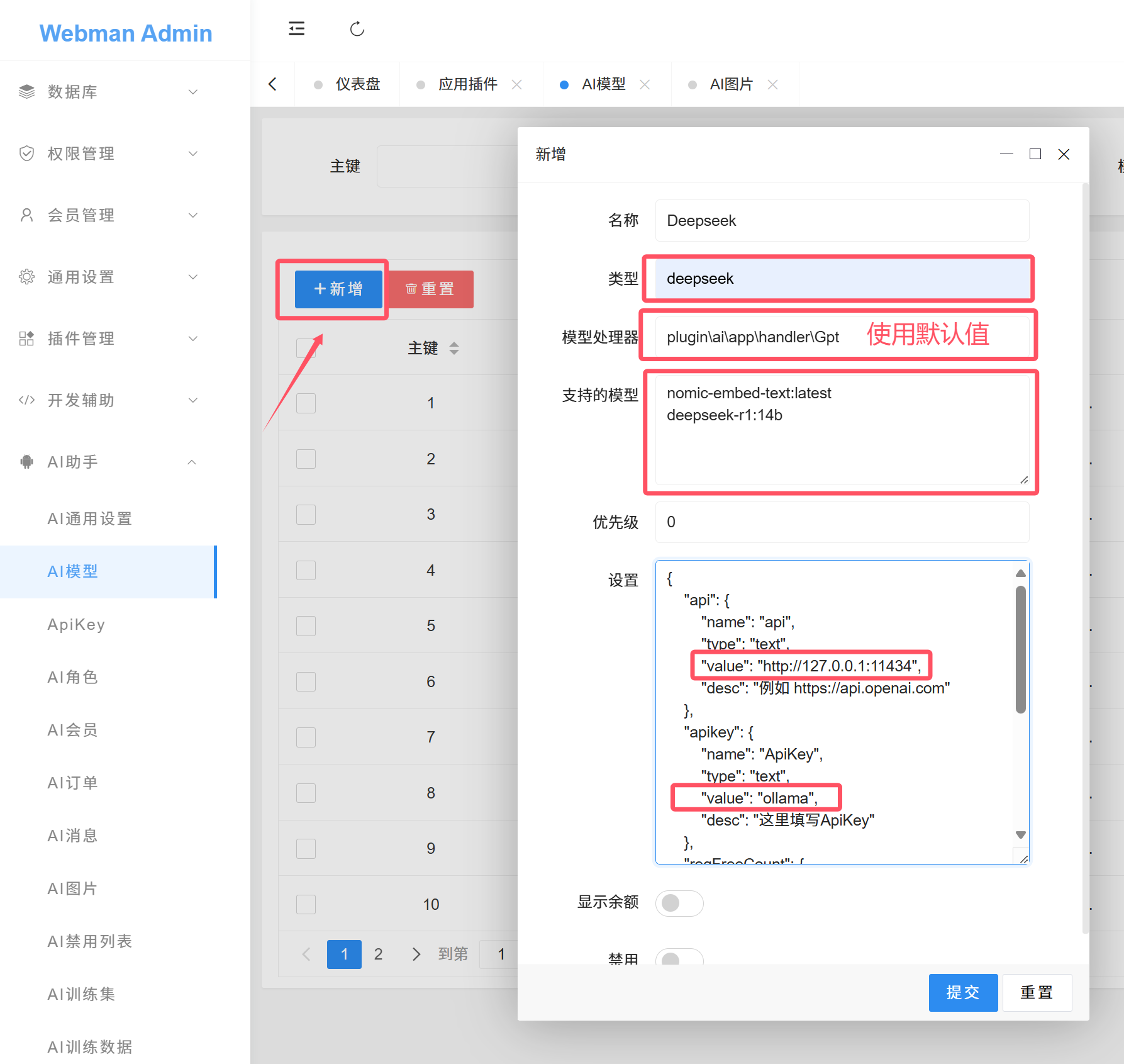
];安装ollama并添加deepseek等相关模型
安装 ollama,并执行
ollama pull nomic-embed-text
ollama pull deepseek-r1:14b提示
nomic-embed-text 是向量模型,训练必须安装
除了 deepseek-r1:14b 还可以选 deepseek-coder-v2:latest qwen2.5:14b 等模型
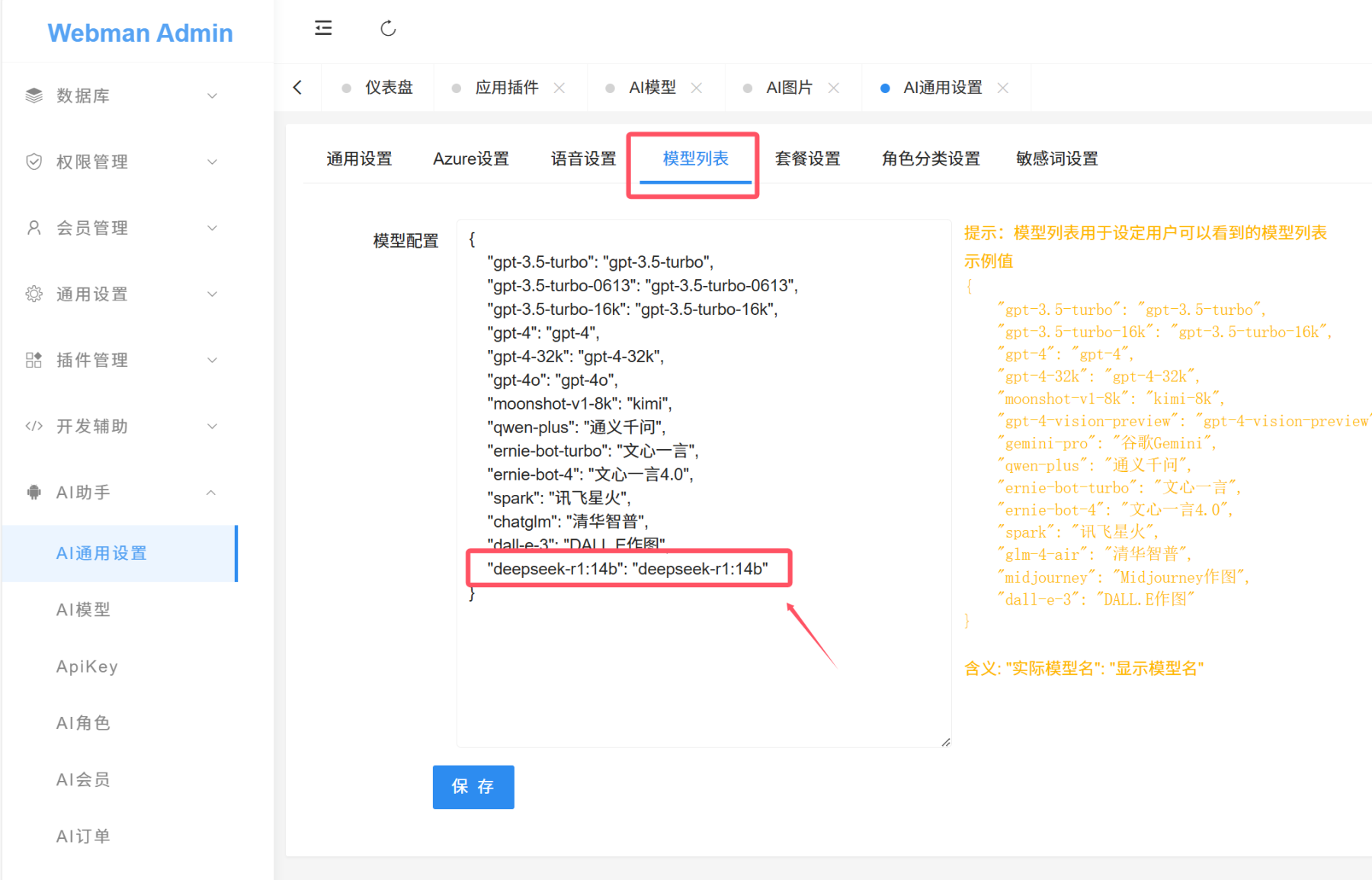
添加deepseek相关模型
步骤四:重启webman
Linux: webman根目录运行 php start.php restart -d
Windows: 按ctl c停止webman,然后运行 php windows.php start
训练过程
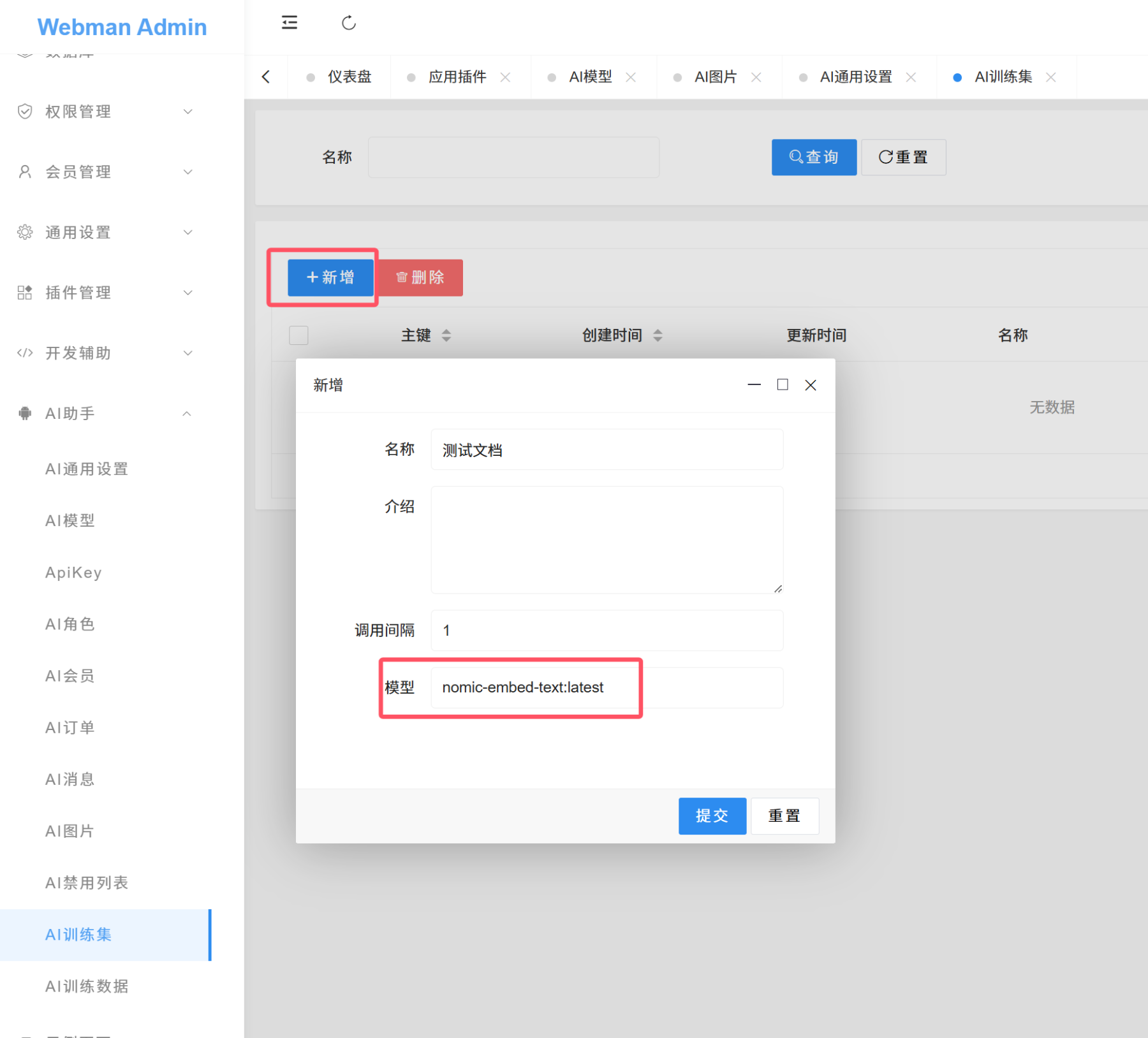
新增训练集
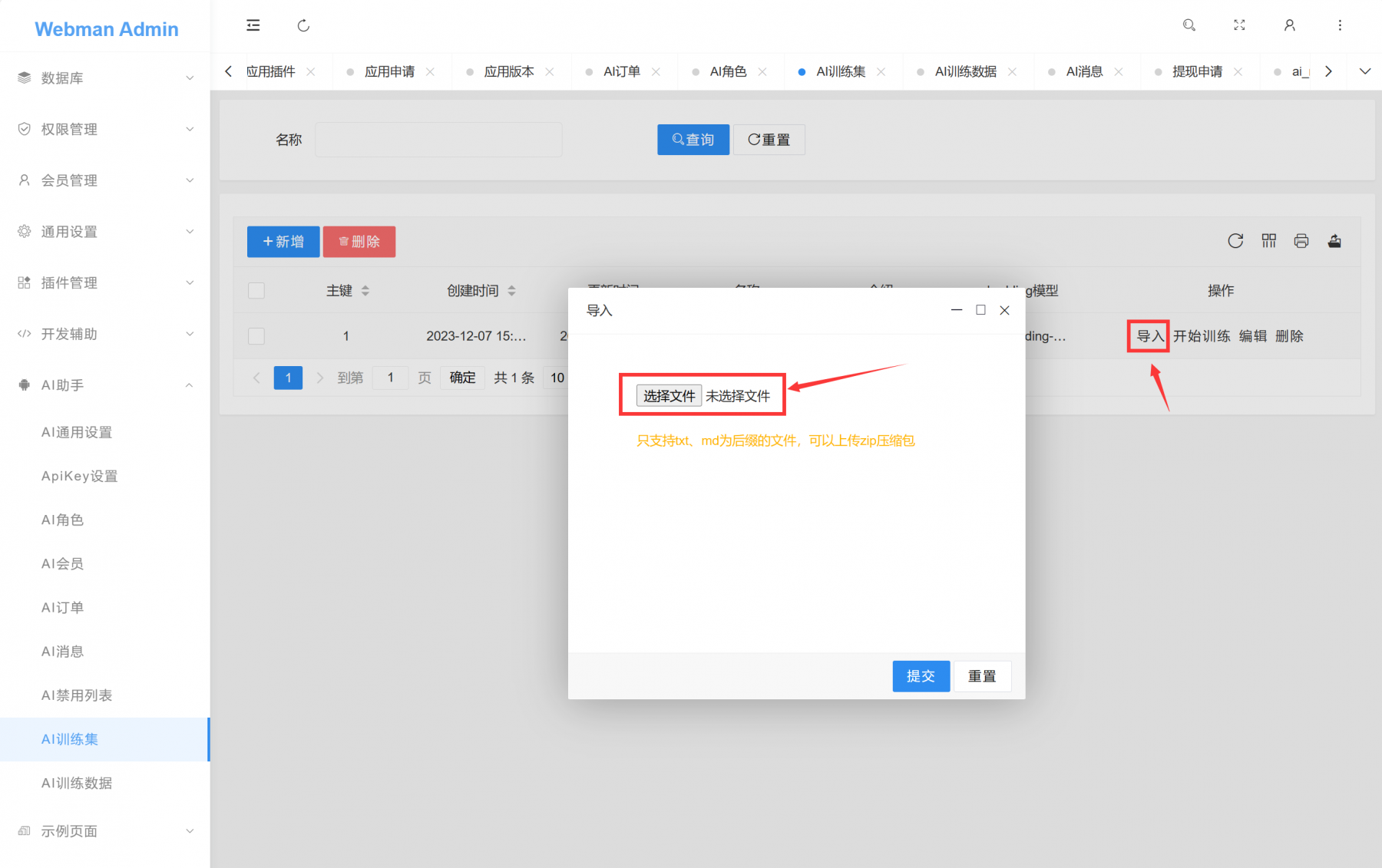
导入数据
提示
如果提示 Class'Redis' not found 是因为没有给PHP安装Redis扩展。
训练的文本样例
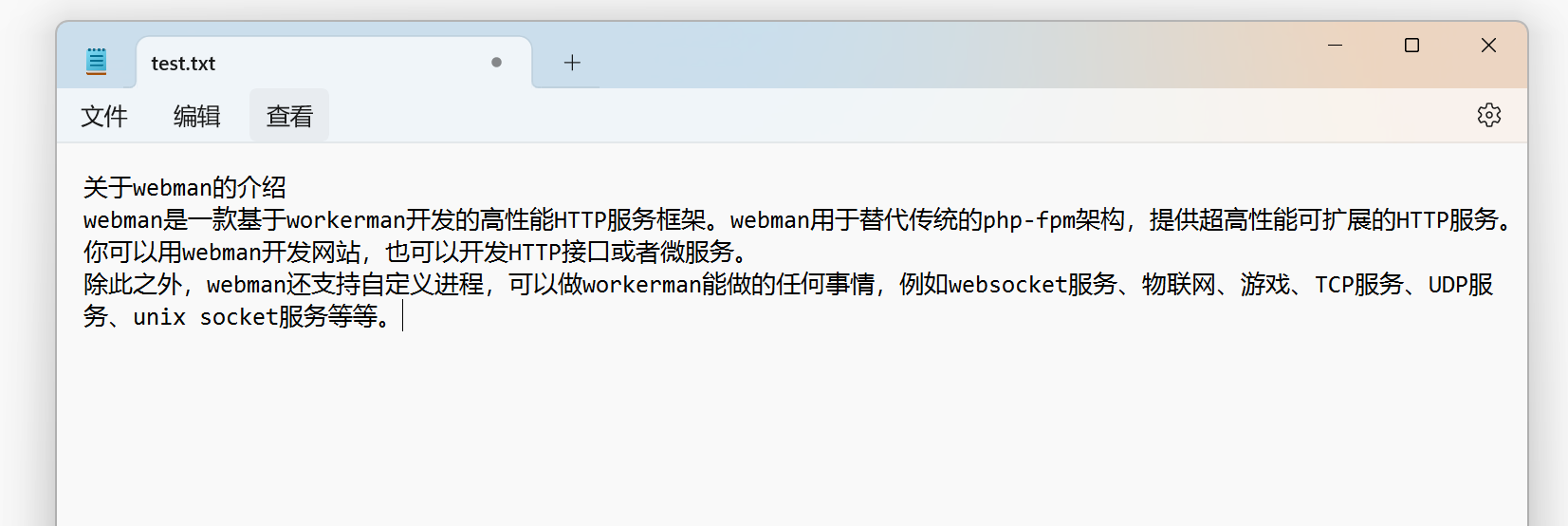
注意:训练内容没有固定格式,训练的数据最好顶部加上一个对本内容的总结性标题或提问,这样效果才会最好。类似上面这个截图
提示
导入数据目前只支持txt和md为后缀的文件,单个文件大小不能大于9k。支持压缩包上传,同理压缩包内每个文件大小不能大于9k。
开始训练
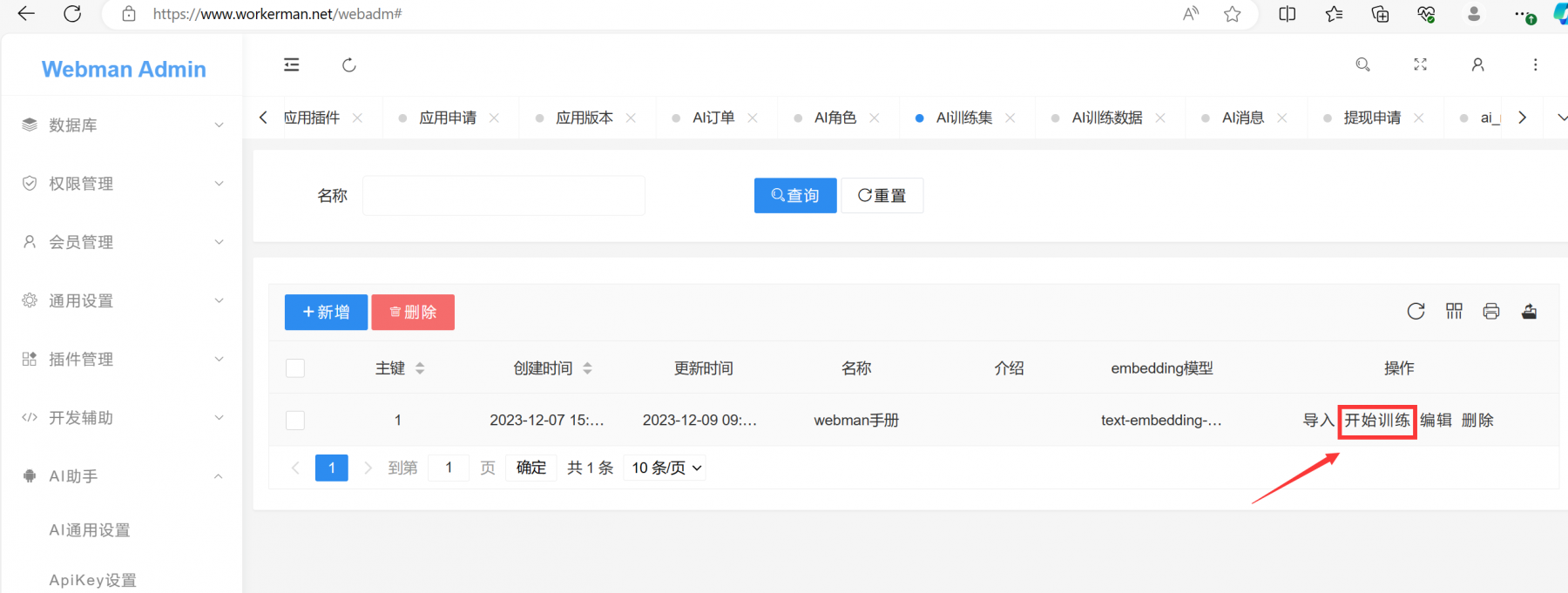
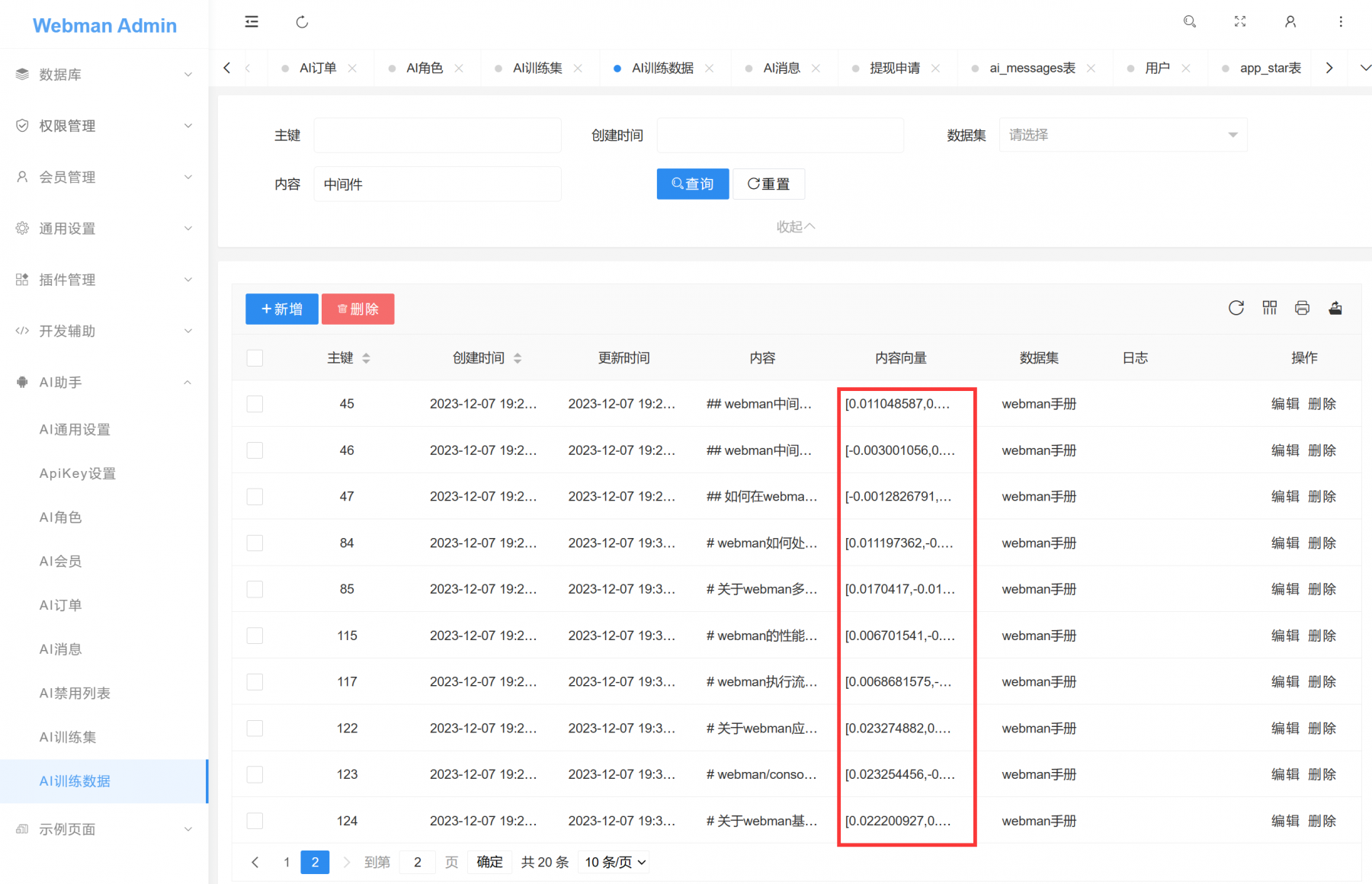
AI训练数据 里的 内容向量 里有值,说明此条记录已经训练完毕,内容向量 同时会在redis-stack里存储一份,用来快速检索。
注意
如果你不想让你训练的模型回复训练内容以外的数据,可以在角色提示词里明示。例如webman手册助手的角色提示词如下:
“webman是一个高性能php框架,你是一个webman助手,以下是webman文档,请根据文档回复,如果无法得到答案或者不是webman相关的问题则回复文档中未找到对应的答案。请确保回复正确。”
设置角色
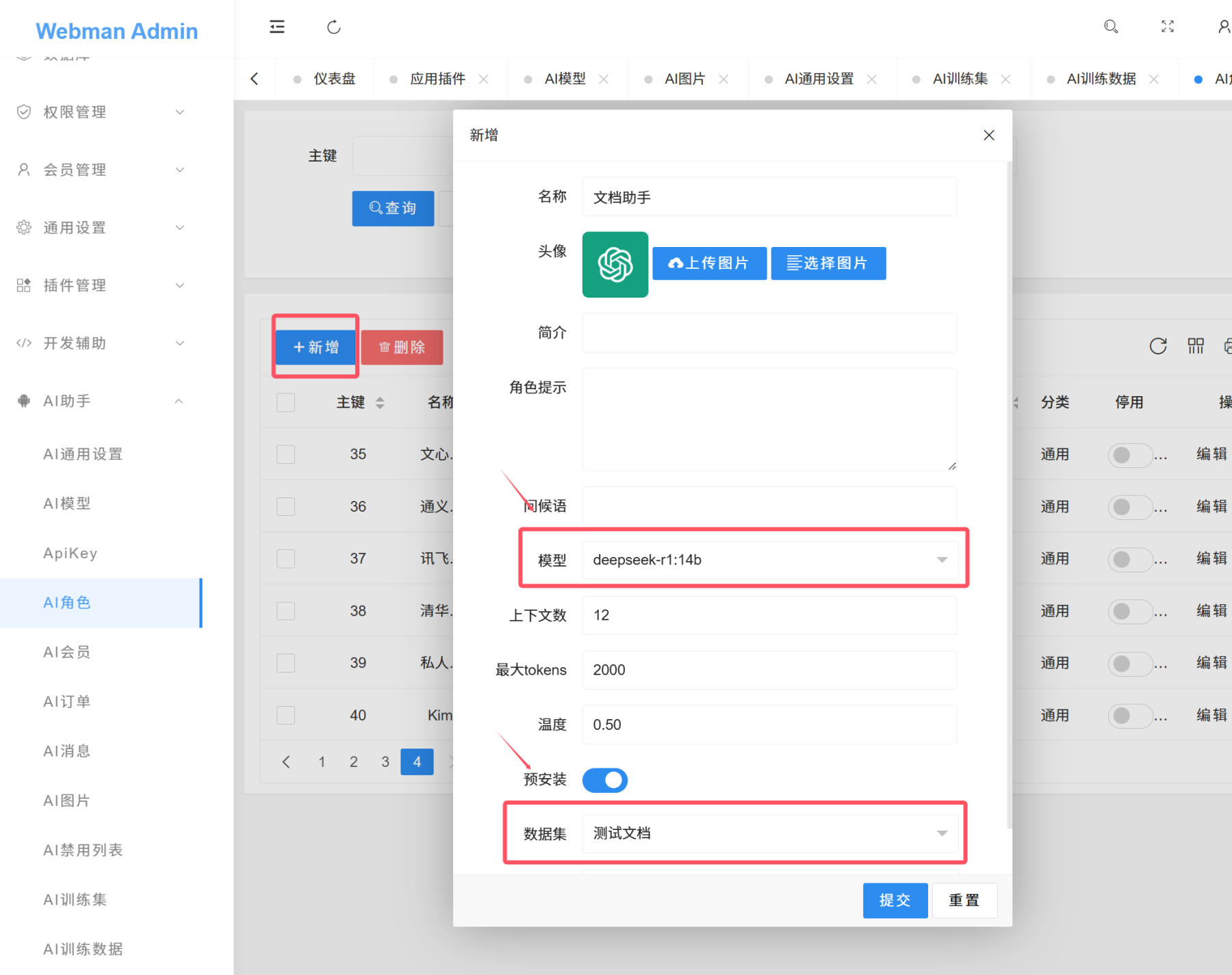
在需要使用训练数据的角色里选择训练集,保存。(前端用户需要刷新页面角色才能生效)
AI就会使用训练集里的数据回复问题。
测试结果
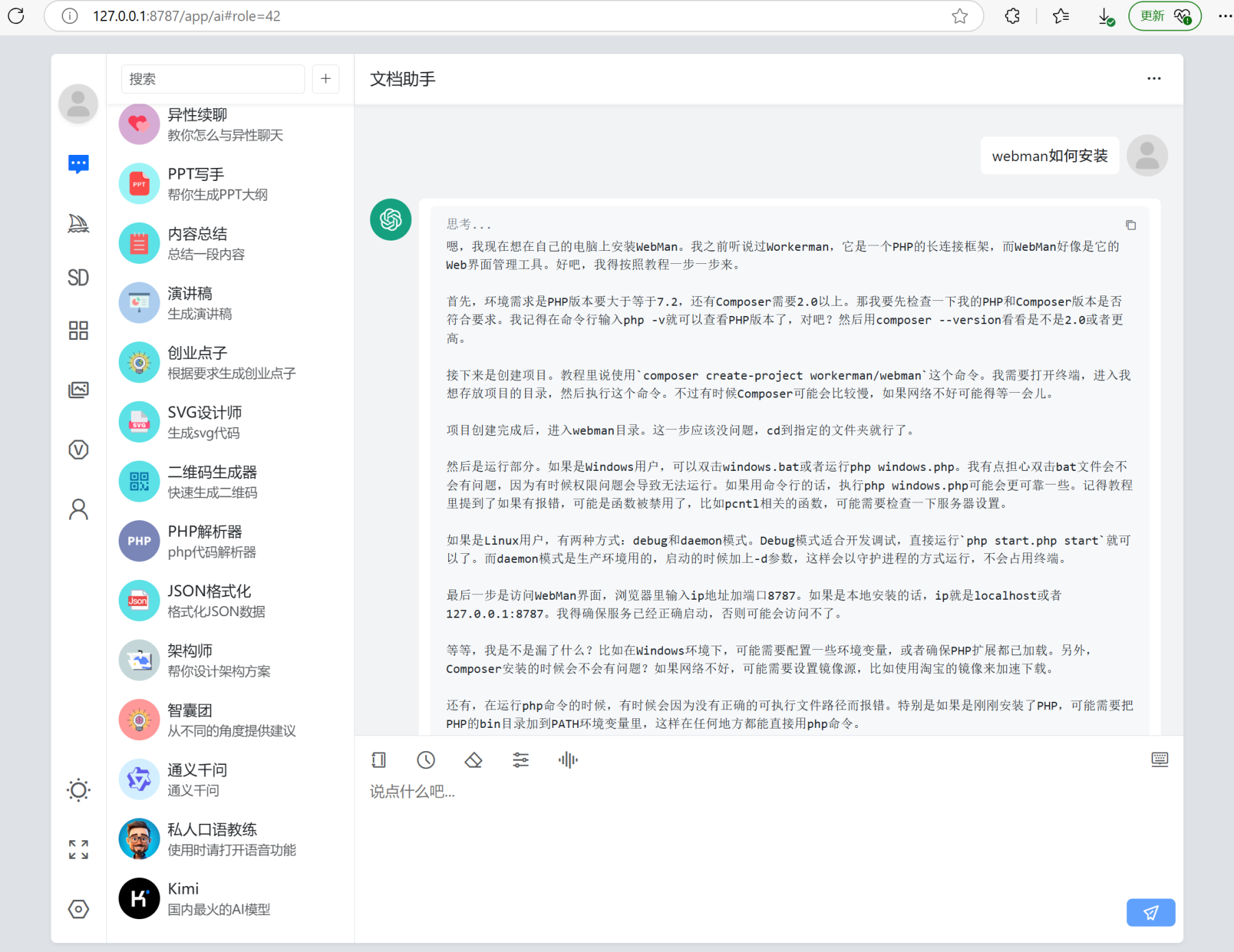
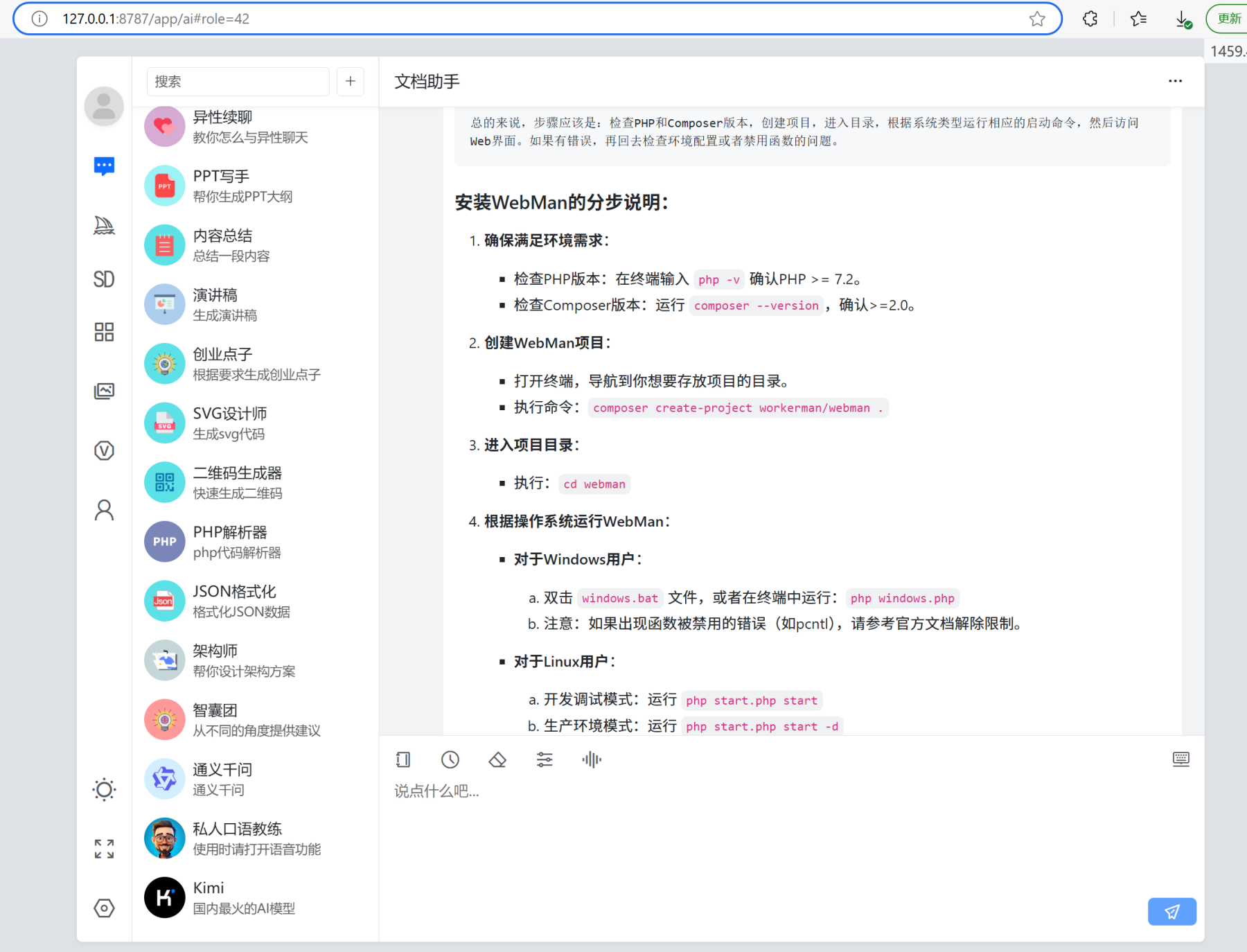






🐂🐂🐂
666
这个要跟上了。顶个!
非常Nice~
大佬,支持使用爬虫从网上抓取站点来生成知识库不?
nomic-embed-text 这个模型,对硬件要求高吗? 不带显卡的x86服务器可以部署吗?
这种问题,要善于AI:
nomic-embed-text 模型对硬件要求较低,尤其适合资源有限的场景,不带独立显卡的x86服务器可以部署。以下是具体分析:
1. 硬件要求
根据对比表格信息,nomic-embed-text 的最低内存需求为 8GB,推荐配置为 16GB+,但实际部署中若仅用于文本向量化等轻量任务,8GB内存通常足够。
模型体积较小,仅需 274MB 存储空间,适合磁盘资源有限的服务器。
虽然该模型支持GPU加速(如NVIDIA显卡可提升推理速度),但非强制要求。Ollama等部署工具会自动检测资源,若无GPU则默认使用CPU运行,仅需确保CPU性能足够(如Intel Core i5或AMD Ryzen 5及以上)。
2. 无显卡服务器部署可行性
多篇教程提到,nomic-embed-text 可通过Ollama在仅CPU的x86服务器上运行,例如在Windows 10或Linux系统中,通过命令行直接拉取并启动模型,无需独立显卡支持。
在无GPU情况下,模型推理速度可能较慢,但对于文本嵌入(如文档向量化、相似性匹配等场景)仍可满足基本需求。实际测试中,普通CPU(如i7-12700)处理中小规模文本任务响应时间可接受。
3. 部署建议
使用Ollama管理模型时,建议通过环境变量设置模型存储路径(如
OLLAMA_MODELS),避免占用系统盘空间。若需提升性能,可通过调整文本分块大小(chunk size)减少单次处理数据量,或结合轻量级向量数据库(如LanceDB)降低资源消耗。
总结
nomic-embed-text 是一款轻量级嵌入模型,对硬件要求较低,无显卡的x86服务器完全能够部署。其优势在于低资源占用和灵活的部署方式,适合个人开发者或中小团队构建本地知识库、RAG(检索增强生成)系统等应用场景。若需处理大规模数据或追求更高性能,可考虑升级CPU或引入GPU加速。
这里写反了
如果服务器不咋地,可以本地链接线上数据库进行训练吧?
老大V5
需要安装本地的话,那线上的webman AI怎么使用deepseek呢
完全照步骤走,不报错也不执行,训练数据列表的“内容向量”也不出来,不知道怎么回事。