webman如何限制cpu占用率,或者如何排查cpu占用高的问题

问题描述
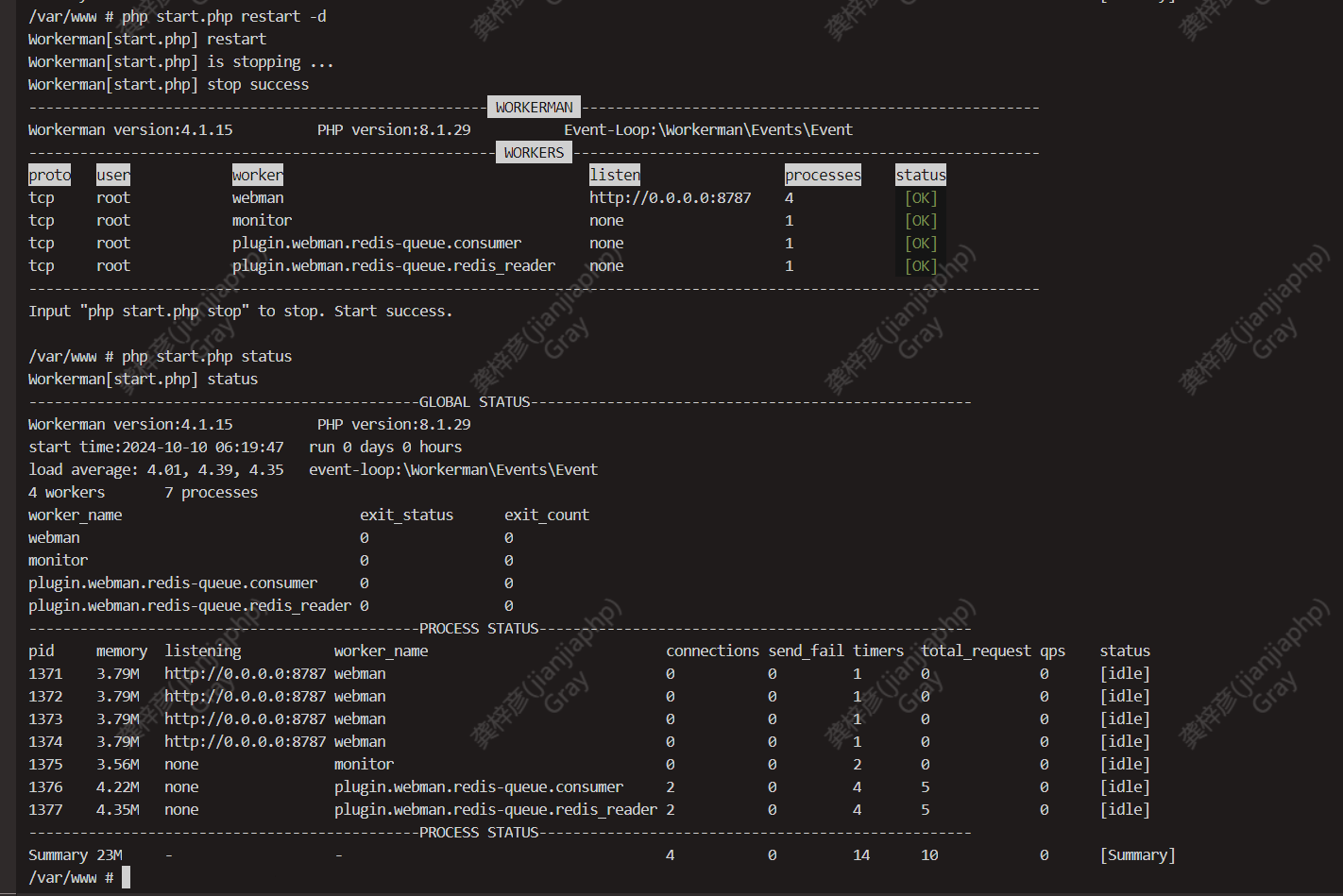
目前该webman服务仅支持redis队列
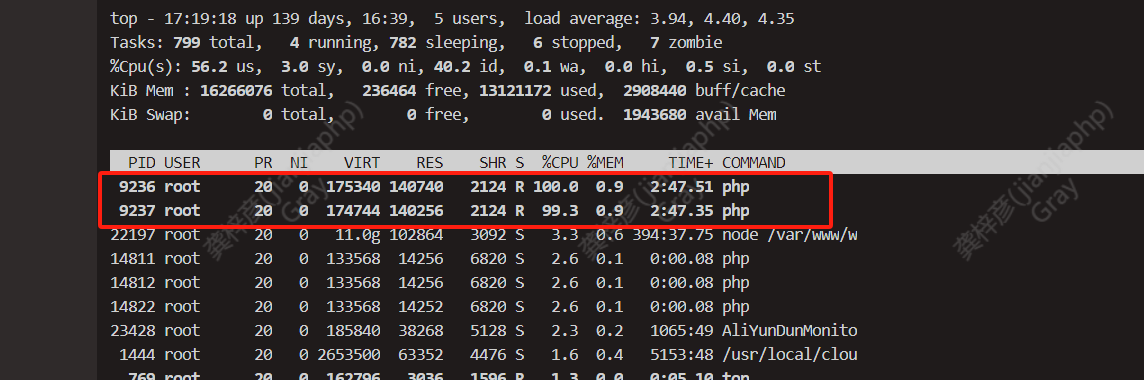
只要一启动直接php的cpu占用直接拉满
程序代码或配置
操作系统环境及workerman/webman等具体版本
系统是 liunx 阿里云的服务器 webman框架 只有redis队列服务 直接cpu拉满不是很清楚原因
并且该服务不需要很大的链接数 只是作为redis消费者的存在
3个回答
相关连接
年代过于久远,无法发表回答





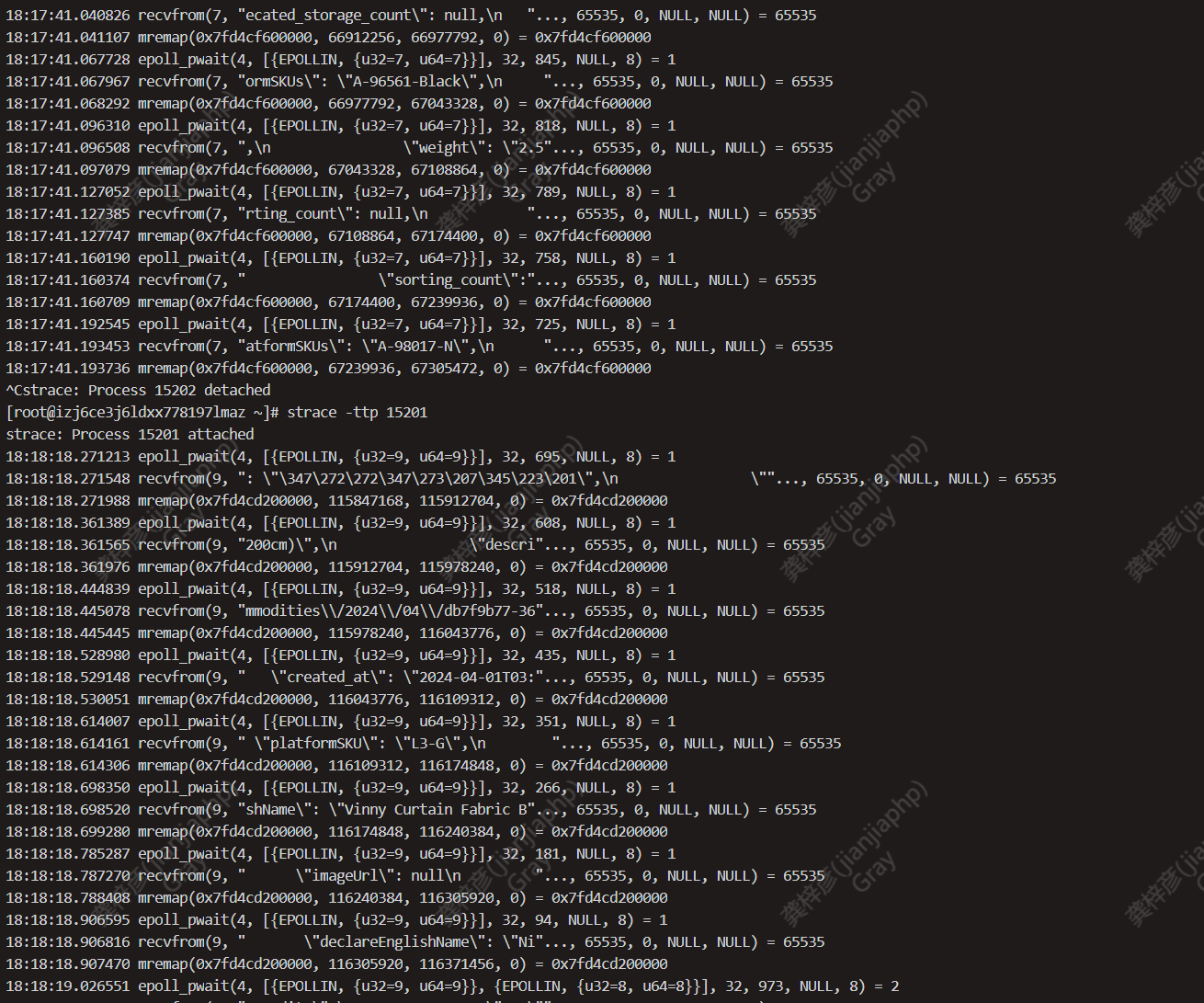
strace -ttp 进程id
我敲 老大 7点就起床了
贴上去了 感觉没啥用
cpu 100%的时候执行
另外看下runtime/logs 下各种日志
其实只要我把他启动了 cpu就直接99%了 还有数据库也99%了
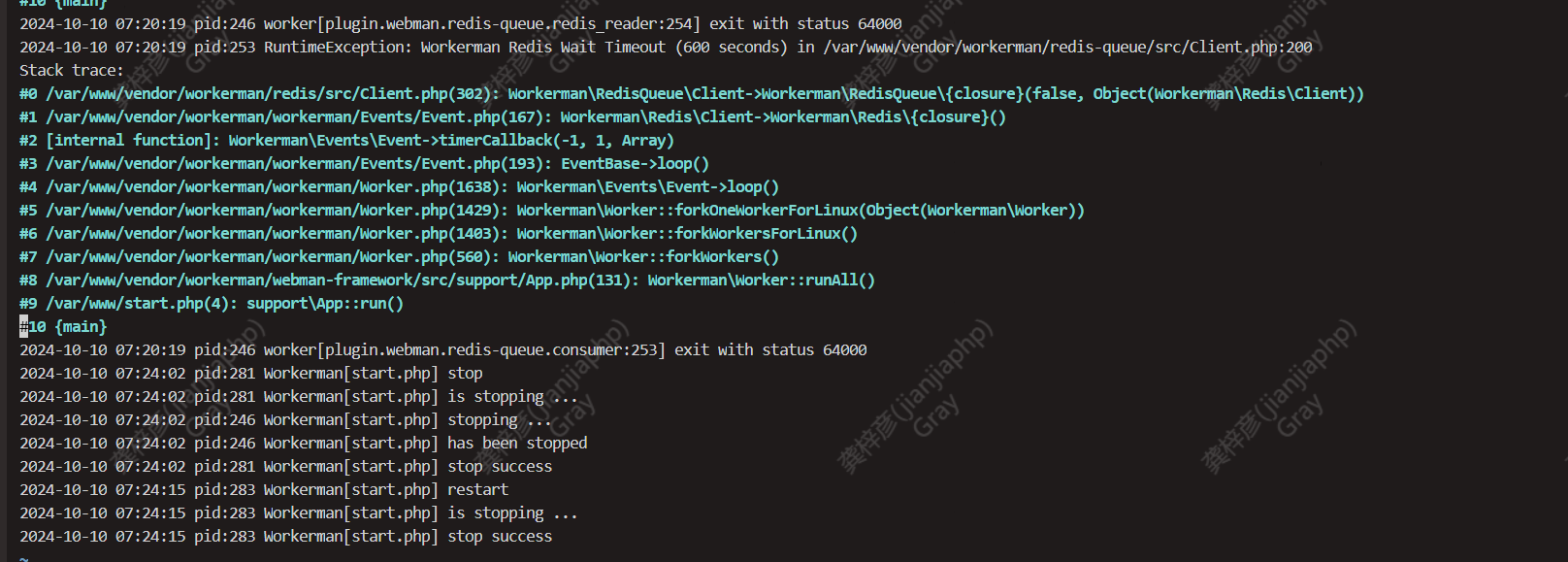
新贴了一张图 runtime/logs 下各种日志 只有这个地方有错误
但是这个错误并不影响业务的处理 redis队列并不会有问题
可能是我重启导致的这个错误
从strace看进程一直在从fd=9的描述符上读取很大的数据,要看下fd=9的描述符是什么
通过命令
lsof -nPp 15021查看fd=9的资源是什么。如果15021进程不存在了,重新strace 看下哪个fd像上图那样一直读数据,然后
lsof -nPp 进程pid看下fd是什么资源。有可能是业务从数据库里读的数据太大了导致PHP和数据库的cpu高。
redis队列 是不是延迟队列 又大数据 ?
估计是 一次处理几十万那种 然后查询的数据也是几十万