使用webman-shared-cache共享缓存,定时上报大并发时,上报进程busy

问题描述
需求:
使用webman提供一个http服务,接收大量的请求(1000w+/天),并将请求根据请求中的参数task_id存储到apcu共享内存中,由新开的进程定时获取共享内存种的数据,每次获取100条,批量存储到redis中,供其他程序使用。
问题:
开了10个上报进程,每个上报进程每10秒会调用Cache::search()获取需要上报的任务,然后加锁此任务,对该任务下的数据进行上报,上报完成后释放任务锁。
随着程序启动时间越长,上报进程会出现busy的情况。此时重启上报进程会恢复[idle]状态,持续一天时间,相同的业务量继续出现busy的情况。
分析
我怀疑是随着apcu的持续使用,导致Cache::search()模糊获取key的方法会越来越慢,所以导致这个问题,但是不知道如何下手解决这个问题。
apcuinfo的信息为:
{"num_slots":4099,"ttl":0,"num_hits":11045579162,"num_misses":692074161,"num_inserts":1451177345,"num_entries":15239,"expunges":0,"start_time":1715919517,"mem_size":3907568,"memory_type":"mmap","mem_size_mb":3.7265}
核心代码为:
public static function push(): void
{
Cache::Search(Cache::WildcardToRegex(Util::TENANT_TASK_PREFIX . '*'), function ($taskKey, $value) {
// 获取待上报任务
list(, $tenantId, $taskId) = explode(':', $taskKey, 3);
// 增加原子锁,保证【是否存在上报的任务】和【任务加锁】的原子性
$isExists = true;
Cache::Atomic('report-lock', function () use ($taskId, &$isExists) {
// 判断是否已经在上报
if (!static::exists($taskId)) {
// 记录不存在标识
$isExists = false;
// 上报任务加锁
static::lock($taskId);
}
});
if ($isExists) {
return;
}
$result = [];
// 每次获取100条通话记录
Cache::Search(Cache::WildcardToRegex(static::getCacheKey() . $taskId . '_*'),
function ($key, $value) use ($tenantId, $taskId, &$result) {
$result[$key] = $value;
});
// 删除已上报的缓存
Cache::Del(...array_keys($result));
// 上报任务释放锁
static::unlock($taskId);
// 上报消息
if (!empty($result)) {
// 分块 每次上报100条
foreach (array_chunk($result, 100) as $messages) {
static::reportMessage($tenantId, $taskId, $messages);
}
}
});
}负载均衡node-1
两周未重启进程情况为:
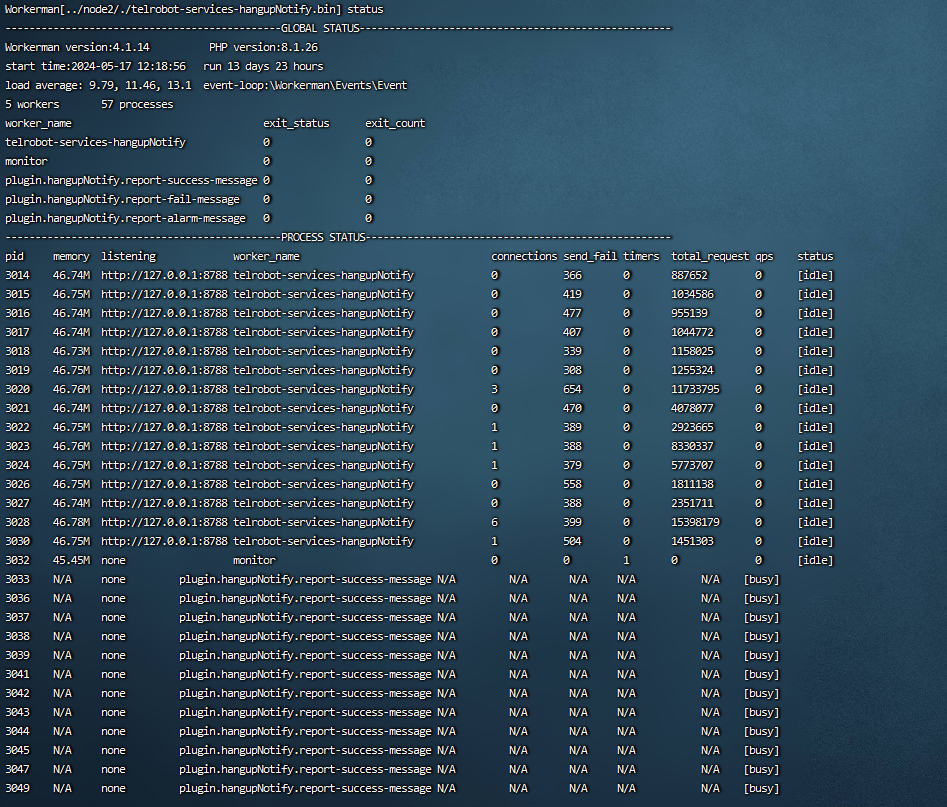
负载均衡node-2
一天未重启进程情况为:
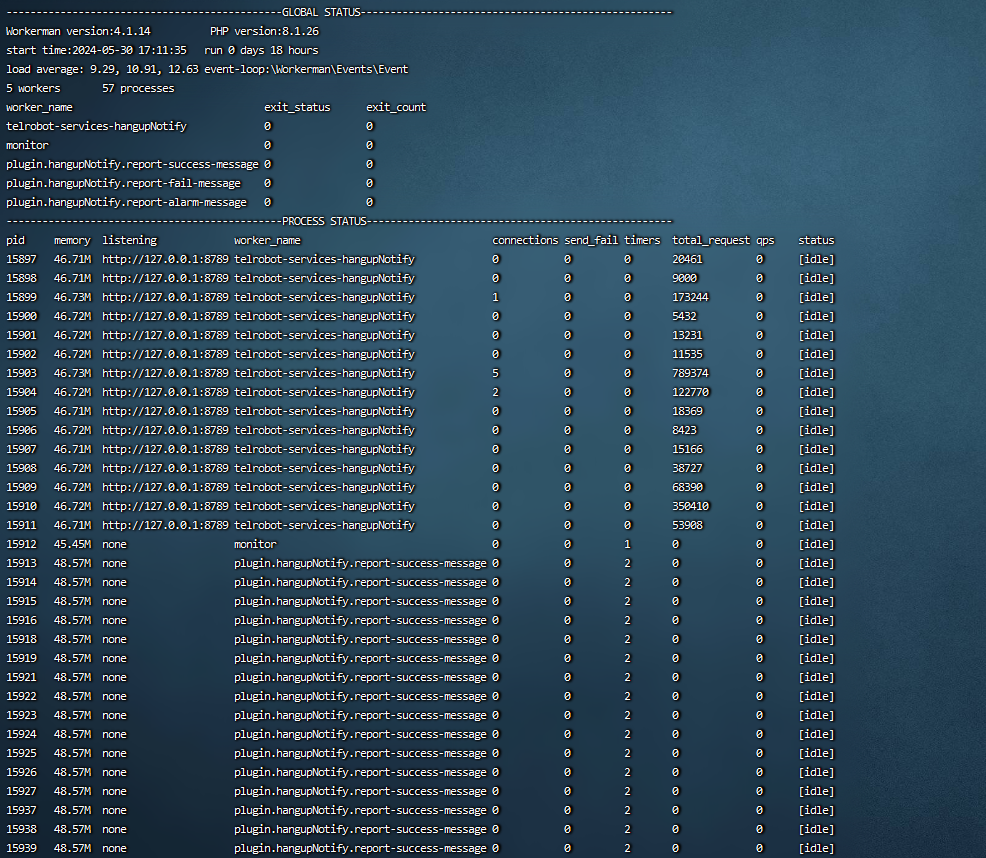
805 2 0
2个回答
相似问题






https://www.workerman.net/doc/workerman/debug/status.html
这里有定位busy的文档。
另外也可以自己记录下怀疑慢操作代码的耗时情况。
感谢,我再研究研究文档
Cache::search()这个函数本质上是O(N)的复杂度,会扫表遍历匹配,不建议在数据量非常大的情况下来做频繁的处理;
在这种业务场景下,我更建议开启进程然后使用Cache的channel进行监听,然后生产端将需要数据推送到channel中,由进程监听消费并更新到对应的数据储存器中
感谢,找到问题了,业务代码的问题,问题是key太多了,没有及时的清理,后面我推送完del掉key就没事了,然后用nignx做了负载到了三个节点分流,目前推送没啥问题了,不过后面如果数据量进一步扩大,就换成channel监听